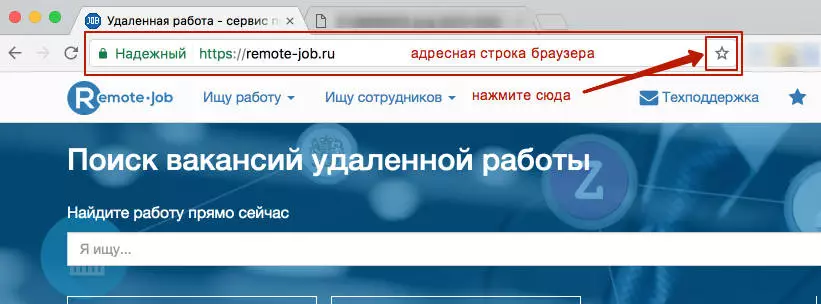
Добавьте страницу в закладки!
Нажмите звёздочку в адресной строке браузера, либо используйте сочетание клавиш " + D"
3 апреля 2025
One Cloud это технологический фундамент для всех продуктов компании. Мы предоставляем единую среду запуска приложений, хранилищ, баз данных и любых других сервисов.
Сейчас One Cloud это 12 000 серверов в 9 дата-центрах, загрузка более 1 000 000 процессорных ядер, объём хранилища в 5000 терабайт и 400 Тбит/сек по сети.
Перед командой стоят задачи развития и масштабирования, повышения надёжности, разработки внутренних инструментов и онбординга новых проектов. Ключевая цель стать самым передовым внутренним облаком среди аналогичных платформ.
Мы ищем Site Reliability Engineer, готовых разделить с нами задачи по эксплуатации, инцидент-менеджменту, R&D, а также принять технический вызов кратного роста облака и амбициозности поставленных перед командой задач.
Стек: Linux, Python, Go, CFEngine, AWX.