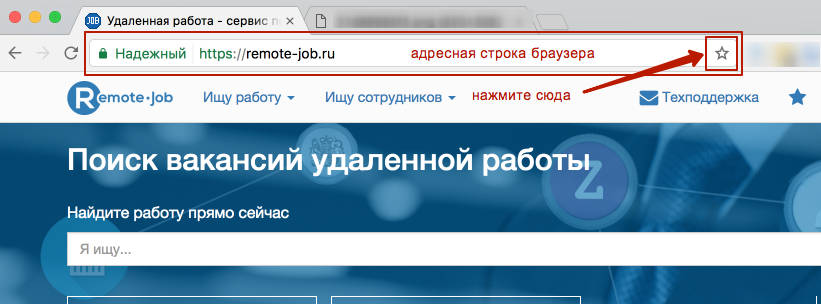
Добавьте страницу в закладки!
Нажмите звёздочку в адресной строке браузера, либо используйте сочетание клавиш " + D"
5 июля 2026
Мы в поиске Middle Data Scientist в команду рекомендательный систем.
Чем предстоит заниматься:
Подойдут два профиля:
Пишем на Python 3.6+ и PySpark 3.0;
Для ресерча доступны два сервера (80 cores, 650Gb RAM), на которых развернут JupyrerHub и есть доступ к Hadoop-кластеру;
Код с логикой ML-пайплайнов упаковываем в Docker и выкатываем, используя CI/CD-инструменты с запуском code style проверок и тестов;
Используем Airflow для управления ML-пайплайнами и запуском их по расписанию;
В командах есть культура code review как для изменений по части продакшен-пайплайнов, так и для ресерч-задач;
Регулярно проводим командные брейнштормы с целью генерации новых идей по развитию наших data-driven продуктов;
В компании внедрена культура принятия решений на основании данных и все изменения тестируем через АБ-эксперименты.