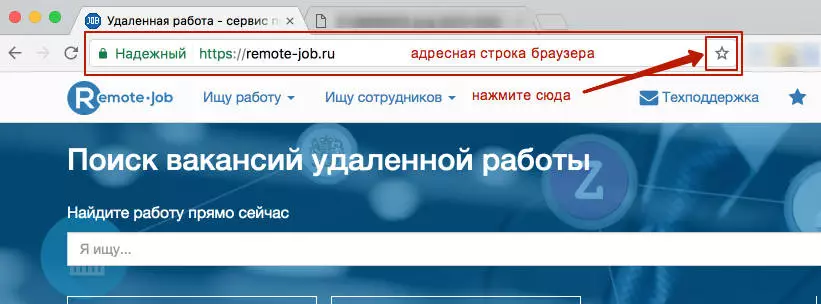
Добавьте страницу в закладки!
Нажмите звёздочку в адресной строке браузера, либо используйте сочетание клавиш " + D"
31 июля 2023
Мы занимаемся развитием и поддержкой платформы Big Data на vk.com. Платформа построена как на проверенных решениях с открытым исходным кодом (Hadoop, Kafka, Spark, Zeppelin), так и на собственных разработках, заточенных под работу 24/7 в условиях высоких нагрузок.
ВКонтакте самая большая социальная сеть в России, поэтому у нас самая большая Big Data:
Ищем специалиста, который отлично владеет любым из этих инструментов.
Вам предстоит:
У нас интересно, потому что:
Мы рассчитываем, что вы:
Приглашаем специалиста, который сможет посещать офис в Москве или Санкт-Петербурге, работать в комбинированном режиме или удалённо. Ждём ваших откликов. Удачи!